


#3 - How does Dragonfly outperform Redis?
Từ những ý tưởng còn già hơn cả bạn và tôi

Trong bài viết trước, chúng ta đã tìm hiểu những lí do khiến Redis dường như đang hụt hơi trong cuộc đua performance.
![[50 Days of S.D] - #2 - Why is Redis so slow?](https://substackcdn.com/image/fetch/$s_!cy0K!,w_140,h_140,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F60294c9c-5257-4f09-bda4-87311bb3ec9f_3011x2415.jpeg)
Một trong những đối thủ nổi bật của Redis là DragonflyDB với throughput gấp 25 lần, và latency p99 chậm hơn Redis chỉ ~0.2ms. Tự nhận là “The Fastest In-Memory Data Store”, DragonflyDB được thành lập bởi kỹ sư người Do Thái Roman Gershman - cựu Principal engineer thuộc team Elasticache của AWS. ℹ️ Nói thêm, Elasticache là một dịch vụ cloud của Amazon, hỗ trợ hầu hết các loại cache phổ biến hiện nay như Redis, Memcached và gần đây là Valkey. Trong thời gian làm việc cho Elasticache, Gershman nhận ra điểm yếu cố hữu của Redis: single-threaded architecture, và manh nha những ý tưởng cải tiến kiến trúc này.
Code giống như một bài thơ
Suốt nhiều năm, team Redis vẫn trung thành với triết lý “simplicity is beautiful and code is like a poem”1. Nhiều lời kêu gọi chuyển đổi sang mô hình multi-threaded đã bị gạt bỏ. Thực tế, có vẻ như đã quá muộn và quá khó2 để refactor Redis khi nó đã hơn 15 tuổi.

Ngày nay, để scale Redis, người ta thường dùng Horizontal scaling, nghĩa là dùng 1 cụm nhiều Redis instance (Redis cluster). Việc này kéo theo nhiều chi phí để vận hành hệ thống: trong 1 cluster N server, xác suất xảy ra lỗi ở ít nhất một server cao hơn khoảng N lần so với một server duy nhất (hint: 1-(1-p)^N ≈ Np). Redis Ltd có vẻ cũng khuyến khích việc này khi mà họ đang bán gói Redis Enterprise với đơn giá $10000/shard 1 năm3 😆.
Sự thật về horizontal scaling

Nỗi ám ảnh về scalability của các BigTech cùng với sự ăn theo của nhiều khóa học system design interview cẩu thả đã khiến nhiều người quên đi một sự thật rằng:
Một hệ thống vertical scaling sẽ tiết kiệm chi phí hơn so với một hệ thống horizontal scaling với cấu hình tương đương cho đến khi nó đạt đến giới hạn vật lý của một server duy nhất.
(Lưu ý, chi phí ở đây là chi phí hardware đơn thuần, chưa tính đến chi phí vận hành). Nhận định trên có thể được chứng minh bằng Root Square Law trong queuing theory:
Bỏ qua phần toán, tôi xin lấy 1 ví dụ minh hoạ thô thiển như sau:
Giả sử chúng ta đang xây dựng 1 storage cluster gồm 16 server (horizontal scaling), mỗi server dự kiến sẽ phải chịu tải 10GB data với độ lệch chuẩn 2GB. Để đảm bảo hệ thống hoạt động ổn định trong peak traffic, chúng ta cần sắm những server với capacity 10+2*2=14 (GB) => như vậy tổng cộng chúng ta cần 14*16=224 (GB).
Nếu chỉ sử dụng 1 server (vertical scaling), chúng ta chỉ cần 10*16 + sqrt(16)*2*2 = 176 GB, thấp hơn ~21.4%.
Tất nhiên trong thực tiễn, việc lựa chọn giữa horizontal scaling và vertical scaling còn phụ thuộc vào các yếu tố khác.
Quay lại với Dragonfly, thay vì fork lại Redis và refactor, Gershman đã chọn lối đi riêng: implement lại một cache service từ đầu sử dụng 1 ý tưởng có lẽ còn già hơn cả bạn và tôi.
Shared-nothing architecture
Shared-nothing architecture lần đầu tiên được giới thiệu bởi Michael Stonebraker trong paper The Case for Shared Nothing xuất bản năm 1986. ℹ️ Stonebraker là cụ tổ của PostgreSQL, ông nhận giải Turing (~Nobel của Khoa học máy tính) vì những đóng góp cho database hiện đại4.
Shared-nothing architecture là kiến trúc trong những hệ thống mà các processor hoạt động độc lập với nhau, không chia sẻ bộ nhớ. Ý tưởng này không mới và đã được ứng dụng trong nhiều hệ thống nổi tiếng như:
MapReduce5: một mô hình xuất phát từ Google. Mô hình này xử lý một lượng lớn dữ liệu bằng cách chia nhỏ input và xử lý chúng song song bằng các server độc lập, rồi sau đó kết hợp kết quả lại.
ScyllaDB6: một bản “clone xịn” của Cassandra. ScyllaDB chia data set thành nhiều phần và mỗi phần sẽ được xử lí độc lập bởi 1 CPU riêng biệt.
Dragonfly áp dụng mô hình này bằng cách chia dataset thành N phần (shard), với N <= số thread của server. Mỗi shard được quản lý độc lập bởi 1 thread duy nhất, theo nguyên tắc:
Making each thread as independent as possible
Điều này giúp Dragonfly tận dụng được tất cả các CPU trong server. Mỗi thread trong Dragonfly sẽ đảm nhiệm ít nhất 1 trong 2 nhiệm vụ chính:
tiếp nhận TCP connection từ client.
hoặc/và thực thi command từ client.

Các thread trong Dragonfly giao tiếp với nhau qua message bus để đảm bảo tính chất “share nothing” của thiết kế. Bạn nào biết Golang có thể hình dung message bus tương tự như Golang channel.
Ví dụ trong hình trên, Client B kết nối tới Thread 3 và muốn thực thi command với data thuộc shard 4. Shard 4 thuộc sở hữu của Thread 4 nên Thread 3 sẽ gửi data tới Thread 4 thông qua message bus và yêu cầu Thread 4 xử lý command từ Client B. Việc xác định shard được thực hiện đơn giản bằng cách lấy hash(key) % N.
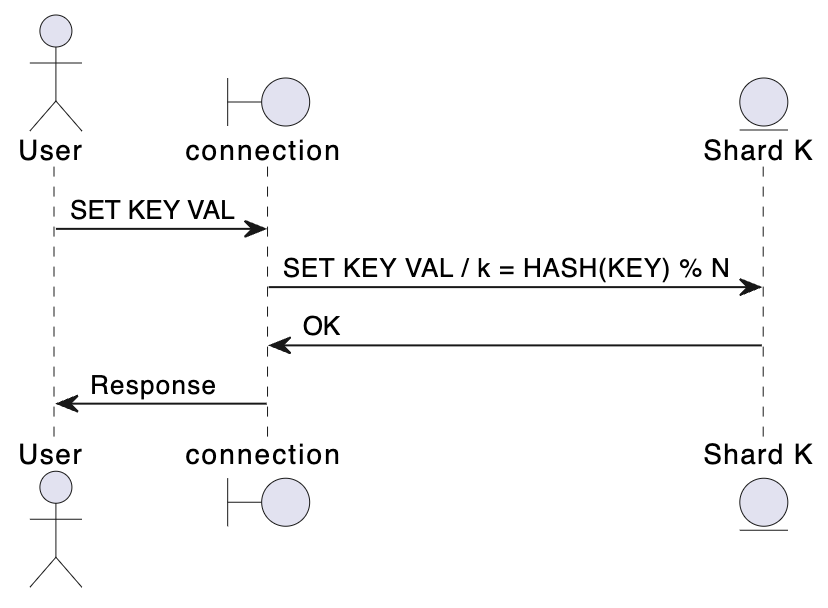
Do mỗi shard được quản lí bởi một thread độc lập, chúng ta không cần dùng tới lock để tránh race condition. Vì vậy Dragonfly, mặc dù sử dụng nhiều thread, vẫn hạn chế được hiện tượng lock contention mà tôi nhắc đến trong bài trước.
VLL, 2Q và DashTable
Ngoài Shared-nothing architecture, Dragonfly còn ứng dụng những thuật toán và cấu trúc dữ liệu tân tiến khác để khắc phục các điểm yếu của Redis:
Transaction: với những command cần được thực hiện atomically trên nhiều shard, Dragonfly sử dụng VLL protocol (Very lightweight locking protocol)7 để hỗ trợ transaction. VLL ra đời năm 2015, được đánh giá tốt hơn các protocol truyền thống như 2PC. Nói thêm, Redis chỉ hỗ trợ transaction kiểu giả cầy, trích từ doc của Redis:
even when a command fails, all the other commands in the queue are processed – Redis will not stop the processing of commands.
Eviction policy: Redis sử dụng “approximated LRU” để giải phóng bộ nhớ. Thuật toán này giả định rằng các key ít được dùng gần đây nhất cũng là những key có ít giá trị nhất. Giả định này không đúng trong nhiều trường hợp, ví dụ khi client access pattern có dạng long tail. Dragonfly sử dụng thuật toán 2Q để khắc phục nhược điểm này. Nói ngắn gọn thì 2Q8 sử dụng cả tính mới (recency) và tần suất để ra quyết định chọn key nào để xóa.
Cache data structure: Dragonfly sử dụng DashTable9 để lưu trữ dữ liệu (key, value). Một thử nghiệm cho thấy cấu trúc dữ liệu này sử dụng ít hơn ~50% bộ nhớ so với HashTable kiểu chaining của Redis10.
Đây đều là những công nghệ thú vị, đúng kiểu “cutting edge”. Hi vọng 1 ngày nào đó tôi có thời gian viết bài về chúng.
Cheers, until next time!
P/S: queuing theory là 1 nhánh toán học nghiên cứu về các mô hình hàng đợi, có nhiều ứng dụng trong IT. Thật tình cờ, gần đây tôi có đọc được một bài viết thú vị từ anh Khai Tran (senior staff eng @Linkedin), nhân tiện đây muốn chia sẻ lại: Học toán để làm gì - Queuing theory in practice.
Hóng bài tiếp theo của sốp
Học và luyện tập gì để clone được Redis hoặc Dragonfly này ạ anh