


#6 - Điểm nóng
On Small cache with big effect and Request Collapsing

Bài viết thuộc series 50 Days of System Design, một series về thiết kế hệ thống dành cho người đọc chậm và muốn hiểu sâu.
Hotspot
Khi lượng dữ liệu tăng lên quá lớn, cách phổ biến nhất để mở rộng hệ thống là partitioning: chia nhỏ tập dữ liệu thành nhiều phần nhỏ, mỗi phần (gọi là 1 partition hay shard) được lưu trữ và quản lý trên một server riêng biệt (shard server).

Tuy nhiên, partitioning thường gặp phải vấn đề hotspot. Vấn đề này xảy ra khi traffic bị phân phối không đều, dẫn đến một số shard nhận được quá nhiều request từ client. Hậu quả là các shard này bị quá tải, thậm chí là crash. Ví dụ: 1 hệ thống database gồm n shard, mỗi shard chứa tối đã 10000 key, mỗi key nhận trung bình 1 QPS. Nếu một key nào đó đột nhiên trở nên cực kỳ phổ biến với QPS = 1000 (ví dụ, sếp Sơn Tùng ra bản hit mới, đội Sky đổ xô vào cày view), shard chứa key đó sẽ trở nên chậm chạp, latency và error rate tăng cao, và cuối cùng có thể bị crash.

Trong bài viết #5, tôi đã giới thiệu kỹ thuật Load Shedding để đề phòng server bị sập bằng cách từ chối xử lý request mới khi server có dấu hiệu quá tải. Kỹ thuật này tuy hiệu quả nhưng lại là hạ sách vì nó đánh đổi một phần availability để duy trì hiệu năng và bảo vệ server. Thực tế, Load Shedding thường đóng vai trò như lớp phòng thủ cuối cùng.

Trong bài viết này, tôi muốn chia sẻ với bạn đọc 2 kỹ thuật thú vị khác để xử lý vấn đề hotspot.
Small cache - big effect
Ý tưởng của kỹ thuật này xuất phát từ một nhận xét rất “tự nhiên”:
the worst case for load balance - a highly imbalanced query workload - is simultaneously the best case for caching, and vice-versa.
// tạm dịch:
trường hợp xấu nhất của load balance - xảy ra khi traffic bị phân phối cực mất cân bằng - lại là trường hợp tốt nhất của caching, và ngược lại.
Dựa trên nhận xét này, ta sử dụng 1 cache server để lưu lại kết quả của những hot key. Nhờ đó, phần lớn traffic của các hot key sẽ được xử lý bởi cache server (vốn có throughput cao hơn shard server nhiều lần).

Câu hỏi đặt ra là Cache server cần có kích thước bao nhiêu để đảm bảo không có shard server nào bị quá tải, kể cả trong trường hợp tệ nhất?
Thật may, các nhà nghiên cứu tại đại học CMU và Intel đã giúp chúng ta trả lời câu hỏi này trong một paper xuất bản năm 2011: Small Cache, Big Effect. Tính toán của họ chỉ ra rằng ta cần lưu O(nlogn) key ở cache server, với n là số lượng shard server. Nghĩa là số lượng key cần cache không phụ thuộc vào số key được lưu trong database cluster mà chỉ phụ thuộc vào số lượng shard server!!! Tôi đã shock khi đọc kết quả này vì nó quá kỳ diệu: giả sử database cluster lưu 1,000,000 key sử dụng n=100 shard, mỗi shard chứa 10,000 keys, cache server chỉ cần lưu vỏn vẹn 8*nlogn+1 ~ 3,600 keys là đủ đảm bảo rằng không có shard server nào bị hotspot (lưu ý logn ở đây là ln(n)).
Kết quả nghiên cứu này hiện đang được áp dụng trong nhiều service tại công ty tôi và chứng minh sự hiệu quả. Bạn đọc tò mò có thể đọc thêm phần chứng minh kết quả ở paper Small Cache, Big Effect nhé (cảnh báo đau mắt vì công thức toán 😅).
Request Collapsing
Kỹ thuật thứ 2 tôi muốn giới thiệu là Request Collapsing (hay còn được gọi là request gating, request deduplication hay singleflight). Ý tưởng của kỹ thuật này xuất phát từ nhận xét: hotspot thường xảy ra khi có quá nhiều request trùng lặp được gửi đến cùng 1 shard.
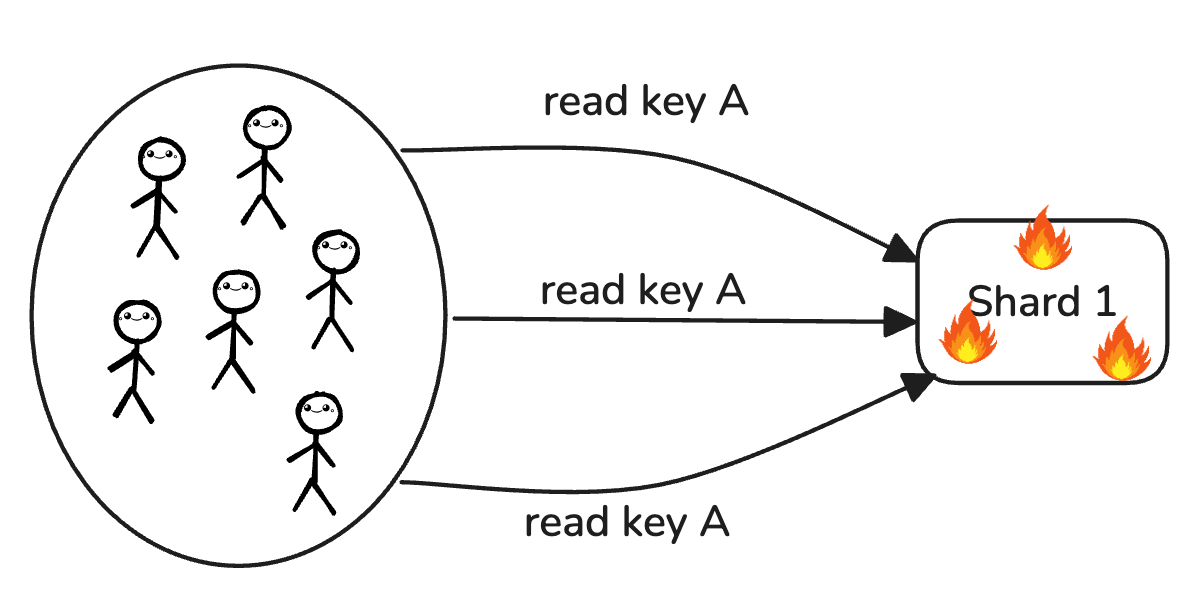
Vì vậy, thay vì gửi đi gửi lại cùng một request, ta chỉ gửi một request đại diện duy nhất, và sử dụng kết quả để phản hồi cho các request trùng lặp còn lại. Điều này đảm bảo tại một thời điểm bất kỳ, với một key A bất kỳ, chỉ có tối đa một request được gửi tới shard server.

Implementation của kỹ thuật Request Collapsing khá đơn giản: khi nhận được request đọc key A từ client, API server sẽ acquire 1 mutex lock cho key A:
nếu có thể acquire lock thành công, API server sẽ gửi request đọc key A xuống Shard server, chờ phản hồi, và sau đó unlock key.
nếu không thể acquire lock (nghĩa là lock đang được giữ bởi một process khác) API server sẽ đợi cho đến khi có phản hồi từ Shard server cho key A.

Req 1, Req 2, Req 3 cùng đọc key A

Mutex Lock ở đây có thể là 1 distributed lock1 (ví dụ Redis) hoặc một local mutex lock. Bạn đọc có thể tham khảo cách cài đặt sử dụng local mutex lock trong thư viện buit-in singleflight2 của Golang (chỉ ngắn hơn trăm dòng code):
func (g *Group) Do(key string, fn func() (interface{}, error)) (v interface{}, err error, shared bool) {
g.mu.Lock()
if g.m == nil {
g.m = make(map[string]*call)
}
if c, ok := g.m[key]; ok {
c.dups++
g.mu.Unlock()
c.wg.Wait()
if e, ok := c.err.(*panicError); ok {
panic(e)
} else if c.err == errGoexit {
runtime.Goexit()
}
return c.val, c.err, true
}
c := new(call)
c.wg.Add(1)
g.m[key] = c
g.mu.Unlock()
g.doCall(c, key, fn)
return c.val, c.err, c.dups > 0
}Lưu ý nhỏ, cách cài đặt trên không đảm bảo tính chất “strong consistency”: trong thời gian Req 2 chờ đợi Res 1 ở API server, giá trị của key A có thể đã bị thay đổi. Nói cách khác, nếu Req 2 không chờ đợi mà được API server gửi ngay lập tức tới Shard server, chúng ta có thể sẽ nhận được một giá trị Res 2 mới hơn. Trong nhiều hệ thống thực tế, “strong consistency” không phải là yêu cầu bắt buộc. Để đạt được “strong consistency”, cần một chút thay đổi trong thuật toán trên, xin phép dành phần này như một bài tập cho bạn đọc.
Kết
Để giải quyết vấn đề hotspot trong partitioning, hai kỹ thuật Small Cache và Request Collapsing thường được kết hợp sử dụng. Đặc biệt, Request Collapsing đóng vai trò bổ trợ hoàn hảo cho Small Cache, giúp ngăn chặn hiệu ứng Thundering Herd - một chủ đề sẽ được phân tích sâu hơn trong các bài viết tiếp theo.
Cheers, until next time!
Fun fact: thư viện Golang singleflight có sự đóng góp của một tác giả người Việt.
👏👏👏
giả sử database cluster lưu 1,000,000 key sử dụng n=100 shard, mỗi shard chứa 10,000 keys, cache server chỉ cần lưu vỏn vẹn 8*nlogn+1 ~ 3,600 keys là đủ đảm bảo rằng không có shard server nào bị hotspot (lưu ý logn ở đây là ln(n)).
Bạn có thể nói 1 cách dễ hiểu hơn tại sao không? Mình đọc paper và thú thật là cũng không hiểu lắm. 🥹