
#7 - Từ Borg tới Kubernetes
Kỷ nguyên vươn mình của container

Bài viết thuộc series 50 Days of System Design.
Lịch sử
Mùa hè 2003, chỉ 1 năm trước ngày Google lên sàn chứng khoán Nasdaq, phó giám đốc công nghệ Urs Hölzle nói với nhân viên: “với tốc độ mở rộng máy chủ như hiện tại, nếu không làm gì đó, (hệ thống của) chúng ta sẽ chết một cái chết tồi tệ vào cuối năm 2004”. Lúc bấy giờ, Google đang sử dụng hàng trăm nghìn máy chủ Linux để phục vụ sản phẩm chủ chốt của mình: Search. Sự phát triển quá nhanh khiến gánh nặng vận hành máy chủ sắp vượt quá sức chịu đựng.
Cuối năm 2003, Borg ra đời với sứ mệnh quản lý mạng lưới server khổng lồ đó. Hệ thống ban đầu chỉ quản lý tài nguyên (CPU, Mem, Disk) ở cấp độ tiến trình (process). Nó giúp “ẩn đi” các chi tiết về quản lý tài nguyên và xử lý lỗi, giúp engineer tập trung vào việc phát triển ứng dụng thay vì lo lắng về hạ tầng. Cái tên “Borg” được lấy theo tên một chủng tộc phản diện trong loạt phim Star Trek.

Borg Queen trong loạt phim Star Trek 2006, Rohit Seth và Paul Menage phát triển cgroups tại Google, 1 tính năng của Linux Kernel cho phép quản lý và giới hạn tài nguyên của 1 nhóm tiến trình.
2008, cgroups được tích hợp vào Linux Kernel v2.6.24, trở thành nền tảng cho công nghệ container. Lúc này, Borg đã là một phần quan trọng tại Google, hầu hết service đều chạy trên những container quản lý bởi Borg.
2010, tại vườn ươm startup YC, Kamel Founadi, Solomon Hykes, và Sebastien Pahl thành lập dotCloud Inc. Ba năm sau, họ đổi tên nó thành Docker Inc và ra mắt Docker, 1 phần mềm quản lý container trên 1 máy chủ dựa trên Linux cgroups và namespaces.

2014, nhằm củng cố ví trí dẫn đầu công nghệ, Google bắt đầu manh nha ý tưởng về một phiên bản open source của Borg. Họ gọi nó là project “Seven of Nine”, cũng là 1 nhân vật trong Star Trek.
Ban đầu, dự án gặp phải sự phản đối dữ dội của Urs Hölzle bởi Borg được xem là bí mật thương mại, là lợi thế cạnh tranh quan trọng bậc nhất của Google.So let me get this straight. You want to build an external version of the Borg task scheduler. One of our most important competitive advantages. The one we don’t even talk about externally. And, on top of that, you want to open source it?
- Urs Hölzle -Cuối cùng, Eric Brewer, phó giám đốc mảng Cloud, đã thuyết phục được Urs về lợi ích1 của việc cho tất cả mọi người, kể cả đối thủ, sử dụng miễn phí Seven of Nine. Dự án sau đó được đổi tên thành “Kubernetes” hay “K8s”.

Logo của K8s, là một đa giác 7 cạnh, lấy cảm hứng từ cái tên gốc “Seven of Nine” Với kinh nghiệm vận hành Borg trong hơn một thập kỷ, Google đã nhanh chóng biến Kubernetes thành công cụ hàng đầu để triển khai và điều phối container cluster. Phần còn lại đã trở thành lịch sử, ngày nay Kubernetes là dự án open source lớn thứ 2 vũ trụ (chỉ đứng sau Linux) với sự đóng góp của ~100,000 contributors, và chiếm > 90% thị phần công cụ điều phối container cluster. Còn Borg vẫn đang bền bỉ quản lý hàng triệu container mới mỗi tuần tại Google.



Kiến trúc của Borg
Disclaimer: mọi thông tin trong phần này lấy từ paper Large-scale cluster management at Google with Borg mà Google xuất bản năm 2015. Borg của 2025 đã khác.
User interface
Từ góc nhìn của user (ở đây là engineer), có 2 loại tác vụ (job) mà họ muốn thực thi trên 1 máy chủ:
long-running service: loại phổ biến nhất, đây là những job cần được chạy liên tục và xử lý các request ngắn, yêu cầu độ trễ thấp. Ví dụ như các dịch vụ Gmail, Google Map, Search.
batch job: tương tự như Linux cronjob, có thể được thực thi 1 lần hoặc định kỳ. Thời gian chạy từ vài giây đến vài ngày, loại này không yêu cầu cao về độ trễ.
Để gửi 1 yêu cầu thực thi lên Borg, user gửi 1 config file lên Borg (thông qua UI hoặc command line tool). Ví dụ config của 1 long-running service đơn giản:
job hello_world {
runtime = { cell = '123' } // ID của cluster muốn sử dụng
binary = '.../hello_world_webserver' // path của program cần chạy
// yêu cầu về cấu hình container
requirements = {
ram = 100M
disk = 100M
cpu = 0.1
}
replicas = 100 // số lượng container
}Borg Design
Borg là 1 hệ thống gốm nhiều cụm máy chủ (cluster) đặt rải rác trên các trung tâm dữ liệu khắp thế giới.

Mỗi cụm máy chủ được gọi là 1 cell, mỗi cell có ~10000 máy chủ, gồm có 2 thành phần chính: BorgMaster và Borglet
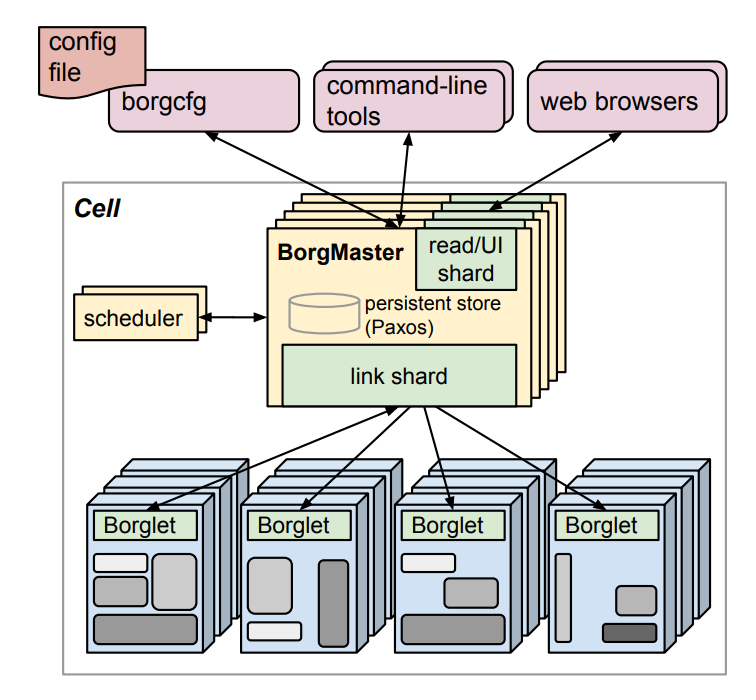
BorgMaster
BorgMaster đóng vai trò trung tâm trong việc quản lý và điều phối các tác vụ (job) trong Borg. Nhiệm vụ chính của nó là tiếp nhận các job từ người dùng, sau đó sắp xếp và phân phối chúng đến các Borglet (các worker server). Để đảm bảo hiệu quả và độ tin cậy, BorgMaster liên tục giám sát trạng thái và tài nguyên (CPU, RAM v..v) của từng Borglet. Điều này cho phép nó chỉ phân phối job đến các Borglet còn đủ dung lượng, đồng thời nhanh chóng chuyển đổi (reschedule) job sang Borglet khác nếu phát hiện một Borglet bị lỗi hoặc ngừng hoạt động.
Để đạt được tính High Availability và Strong Consistency, mỗi cell có một cụm gồm 5 BorgMaster. Cụm này hoạt động theo giao thức đồng thuận Paxos, với 1 BorgMaster đóng vai trò leader tiếp nhận các update request từ users và 4 BorgMaster còn lại là followers. Thiết kế này cho phép hệ thống Borg cell tiếp tục hoạt động ổn định ngay cả khi có tới 2 node BorgMaster bị lỗi. Kubernetes sử dụng một giải pháp tương tự nhưng thay vì Paxos, nó dùng giao thức đồng thuận Raft.
Mặc dù đã có vài nỗ lực nhằm thay thế Raft bằng 1 distributed database như PostgreSQL hay MySQL2 , mình cho rằng các giao thức đồng thuận vẫn là lựa chọn tốt hơn vì:
rất khó đạt được Strong Consistency + High Availability khi sử dụng distributed database.
data mà BorgMaster quản lý ở dạng đơn giản (key-value) và kích thước khá nhỏ.
Paxos/Raft nhẹ hơn đáng kể so với 1 cụm distributed database, giúp giảm chi phí vận hành.
BorgMaster lưu trữ 2 thông tin quan trọng trong Paxos store: 1) trạng thái của các node trong cell và 2) thông tin về các job được gửi lên bởi user. Hai thông tin này được gửi xuống các Borglet node và update định kì bởi 1 vòng lặp đối chiếu (reconciliation loop):
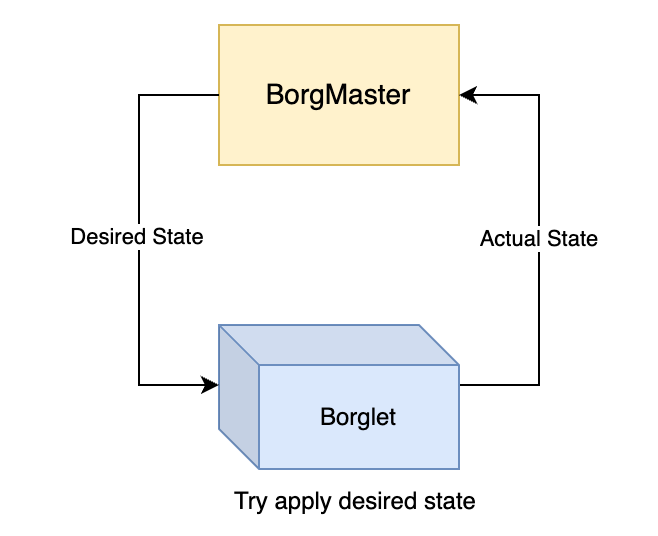
BorgMaster gửi trạng thái mong muốn xuống Borglet (ví dụ chạy một job hello_world) => Borglet áp dụng trạng thái mong muốn đó lên máy chủ của mình => Borglet báo cáo lại trạng thái hiện tại của nó cho BorgMaster => BorgMaster so sánh với trạng thái mong muốn hiện tại trong Paxos store, tính toán các điểm khác biệt, và lặp lại chu trình này.
Vòng lặp đối chiếu này góp phần tăng khả năng tự phục hồi (self-healing) của hệ thống: khi BorgMaster hoặc Borglet bị lỗi và restart, chúng chỉ cần tiếp tục vòng lặp và cuối cùng hội tụ về trạng thái mong muốn. Mặt khác, nó cũng giúp tăng khả năng mở rộng (scalability) vì mỗi Borglet sẽ tự chịu trách nhiệm cho trạng thái của mình mà không bị thắt cổ chai ở BorgMaster.
Một thành phần quan trọng khác của BorgMaster là Scheduler, chịu trách nhiệm chính trong việc lên kế hoạch phân bổ các tác vụ đến các Borglet. Quá trình này gồm 2 bước:
Bước 1: Kiểm tra tính khả dụng của Borglet (Feasibility check): Scheduler sẽ dựa vào thông tin có trong Paxos store, liệt kê ra các Borglet có thể đảm nhận job X.
Bước 2: Chấm điểm (Scoring): Sau khi tìm thấy một tập hợp các Borglet khả thi, Scheduler sẽ sử dụng các thuật toán phức tạp (nếu bạn tò mò có thể tìm kiếm từ khóa bin-packing problem) để chọn ra máy tối ưu nhất để chạy tác vụ.
Mục tiêu của Scheduler là đảm bảo thực thi hết jobs của users trong khi vẫn tối ưu độ khả dụng của toàn hệ thống.
Borglet
Borglet là 1 tác nhân (agent) chạy trên mỗi máy chủ trong “cell”. Nó đóng vai trò như một cánh tay phải của BorgMaster, thực hiện các lệnh và báo cáo trạng thái cục bộ:
khởi động/ dừng/ khởi động lại job.
quản lý tài nguyên cục bộ: CPU, Memory, Disk …
báo cáo trạng thái lên BorgMaster.
hoạt động độc lập: một điểm đáng chú ý là Borglet có thể tiếp tục hoạt động và duy trì các tác vụ đang chạy ngay cả khi nó mất liên lạc với BorgMaster.
Borglet sử dụng 2 tính năng của Linux Kernel để quản lý job:
cgroups: phân bổ, giới hạn và ưu tiên tài nguyên hệ thống cho các nhóm process (container).
namespaces: tạo môi trường tách biệt giữa các container khác nhau. Điều này đảm bảo tính độc lập và bảo mật giữa các job khác nhau.
Kubernetes
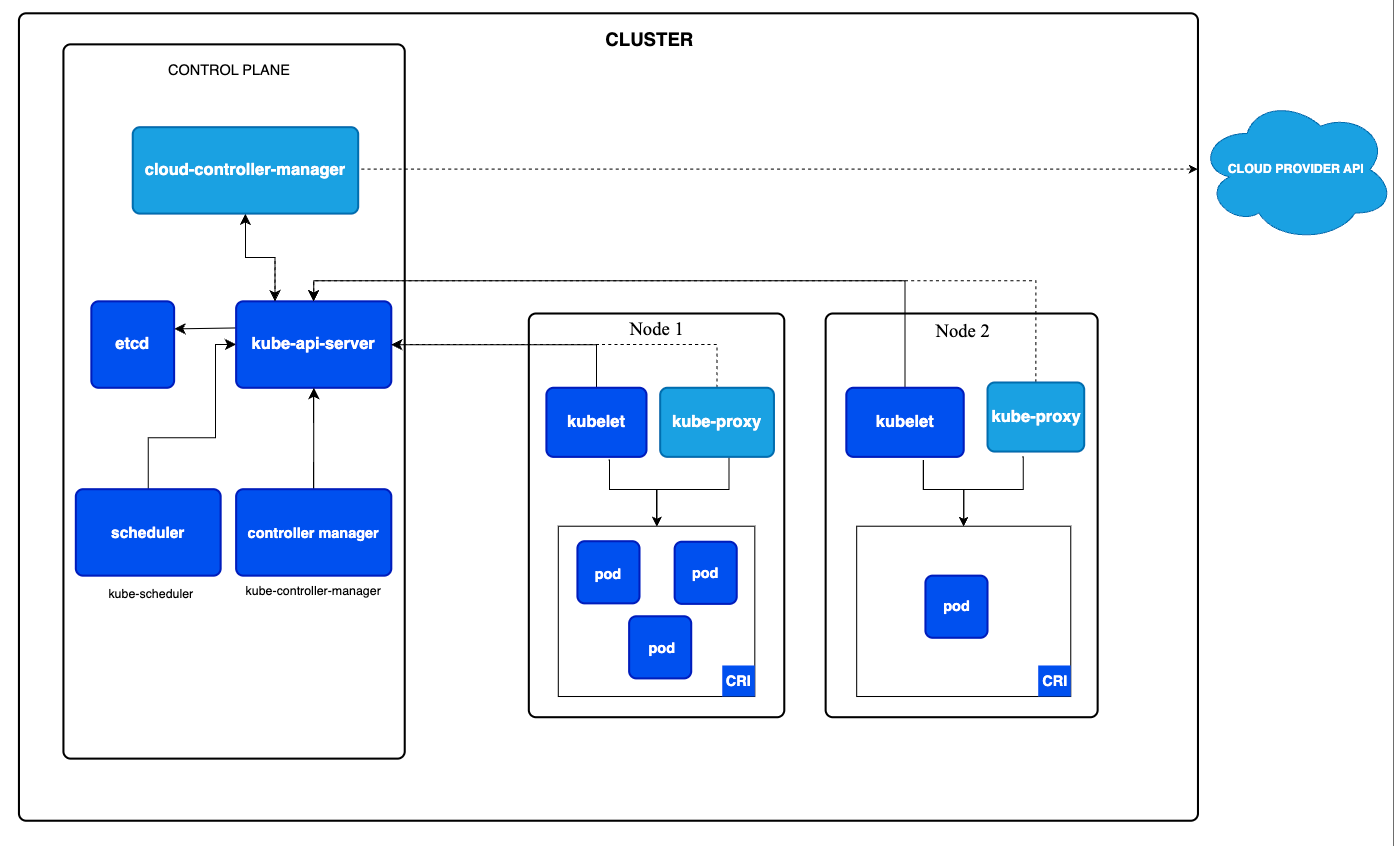
K8s kế thừa nhiều quyết định thiết kế từ Borg, nhiều khái niệm có thể map 1-1 với Borg:
etcd ~ Paxos store
Control Plain ~ BorgMaster
Kubelet ~ Borglet
kube-scheduer ~ Scheduler
Pod ~ Job
Kết
Mỗi khi tìm hiểu về một thiết kế hệ thống, mình luôn cố gắng rút ra những mô hình chung có thể áp dụng cho các bài toán khác. Với Borg/K8s, mô hình kinh điển chính là việc có một nhóm 'master server' dùng Paxos/Raft để đồng bộ hóa và lưu trữ metadata, từ đó quản lý toàn bộ cụm 'worker server'. Đây là một kiến trúc rất phổ biến và bạn có thể thấy nó xuất hiện ở nhiều hệ thống khác như Windows Azure Storage hay Apache Mesos.

Cheers, until next time!


Sau khoảng 4 5 năm đắm chìm vào k8s, từng phải thức xuyên 2 ngày 1 đêm để recover một cluster k8s (tất nhiên là không có HA, món nợ kĩ thuật lớn mà tiền bối để lại) sống dậy từ cõi chết, sục sạo qua rất nhiều các plugin, giải pháp của k8s, cũng như đào sâu vào những thứ khù khoằm nhất như scheduler và customize cái của nợ ấy để fit với yêu cầu của hệ thống (bằng 1 tỉ cái CRDs) thì em chợt nhận ra rằng, có lẽ chúng ta phải to ít nhất phải bằng cọng lông chân của Google thì thực sự k8s mới đem lại lợi ích, tức là phải có tầm 100 200 cái server, hoặc bèo nhất cũng là 50 60 cái, còn không thì đúng là quá phí tài nguyên và công sức để manage 1 cái cluster k8s có 5-10 con máy. Tiền ấy chạy ECS và Fargate có khi còn đỡ mệt hơn.
Đến giờ em nhận ra rằng hoá ra mình chả hiểu cái mẹ gì về k8s hết, chỉ là mình dùng với nghịch nó nhiều nên thành ra quen (giống John von Neumann từng nói, là chúng ta chả hiểu mẹ gì về toán học mà chúng ta chỉ quen với việc sử dụng nó thôi). Sau một thời gian ác mộng với nó thì em nhận ra rằng khi khởi đầu thì tốt nhất đừng dính tới k8s, mà kể cả to rồi chưa chắc đã cần đến k8s, mà ngay từ đầu phải chỉnh đốn cái tư duy microservice, xé 1 cái to thành tỉ cái nhỏ rồi đau đớn vì nó. Lúc này ta nên để ý tới việc xây dựng business và làm cái gì đó ra hồn hơn là tốn thời gian cho 1 cái orchestrator hay ngồi nghĩ xem nên tách cái này ra thành bao nhiêu phần.
Gần đây em có dự định dùng Docker để chạy DB trên production, sau khi search thì mới biết nên tránh dùng Docker để chạy DB trên production, nên dùng cho môi trường dev và test thôi.
Trong bài viết này Google đã dùng Borg ở thời kỳ đầu rồi dần "Tiến hoá" lên Docker, vậy họ có chạy DB bằng Docker trên production không anh nhỉ? Hay dùng một giải pháp khác vậy anh?
https://myopsblog.wordpress.com/2017/02/06/why-databases-is-not-for-containers/
https://thehftguy.com/2016/11/01/docker-in-production-an-history-of-failure/